Lazychains - dynamically populated singly linked lists¶
Contents:
Introduction¶
The lazychains package provides support for chains, which are singly linked lists of items whose members are incrementally populated from an iterator. For example, we can construct a Chain of three characters from the iterable “abc” and it initially starts as unexpanded, shown by the three dots:
>>> from lazychains import lazychain
>>> c = lazychain( "abc")
>>> c
chain([...])
We can force the expansion of c by performing (say) a lookup or by forcing the whole chain of items by calling expand:
>>> c[1] # Force the expansion of the next 2 elements.
True
>>> c
chain(['a','b',...])
>>> c.expand() # Force the expansion of the whole chain.
chain(['a','b','c'])
As we will see, chains are generally less efficient than ordinary arrays. So, as a default you should definitely carry on using ordinary arrays and tuples most of the time. But they have a couple of special features that makes them the perfect choice for some problems.
Chains are immutable and hence can safely share their trailing segments.
Chains can make it easy to work with extremely large (or infinite) sequences.
Expanded or Unexpanded¶
When you construct a chain from an iterator, you can choose whether or not it should be immediately expanded by calling chain rather than lazychain. The difference between the two is pictured below. First we can see what happens in the example given above where we create the chain using lazychain on “abc”.
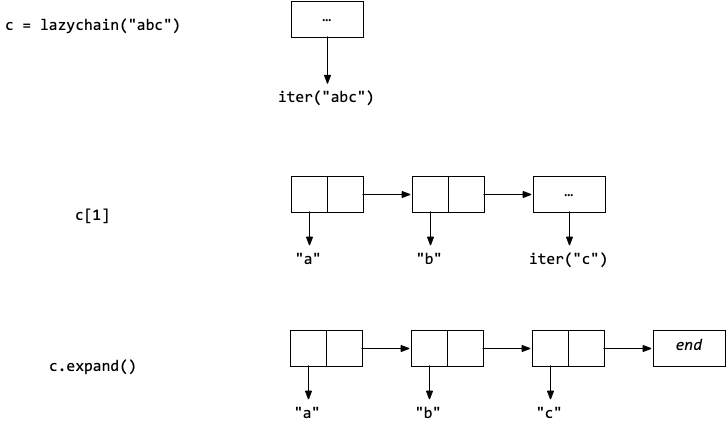
By contrast, we would immediately go to a fully expanded chain if we were to simply apply chain:
>>> from lazychains import chain
>>> c = chain( "abc" )
>>> c
chain(['a','b','c'])
>>>

Array-Like¶
Most array operations work fine on chains. You can index them, take their length, check they are empty with bool(c), concatenate them with +, and check if items are members with ‘in’.
However, it is important to keep in mind that these operations often involve traversing many nodes of a chain. This is in sharp contrast to arrays, where checking the length or getting the length is almost instant.
It’s not all bad news. Iteration and copying is as fast or faster than the same for arrays. And in the next section you will several examples where chains can be a better choice.
Working with Large Chains¶
Chains are relatively bulky and quite possibly extremely long (e.g. all the tokens of a file). As a consequence we want to take advantage of the fact that they are incrementally populated. In order to do this, we have to ensure that we overwrite any references to the start of the original chain.
For example, we might want to iterate over all the tokens of a file, expanding macros as we go. This is the kind of code that we would write.
def tokens( srcfile ):
with open( srcfile, 'r' ) as src:
for line in src:
yield from line.split()
def process_tokens( srcfile ):
tokchain = lazychain( tokens( srcfile ) )
while tokchain:
tok = tokchain.head()
tokchain = tokchain.tail()
if tok in MACROS: # MACROS[tok] will be a list of tokens to substitute.
chain( MACROS[tok] ) + tokchain
else:
do_process( tok ) # Whatever we wanted to do.
As we progress down the chain of tokens, the chain will potentially grow bigger and bigger. By overwriting the ‘tokchain’ variable, we lose all references to the old Chain object. This will allow the Python store manager to promptly reclaim the object.
Implementation Note¶
Once a Chain node that is based on an iterator is expanded, the reference to the underlying iterator is lost. This is an important implementation detail that makes lazychains practical.
How does this work? Hopefully you can see that Chain objects have one of several possible states at any one time:
Unexpanded - with a reference to an iterator.
Expanded and non-empty - with references to the member and the remainder of the chain, which is just another Chain object.
Expanded but empty - and references are cleared.
We arrange that only the unexpanded node at the end of a chain retains a reference to the iterator/lazycall in a slot that is overwritten by the expansion. So once the list is expanded, there are no unexpanded nodes and hence no unwanted references. The iterator can then be garbage collected.
And exactly the same implementation trick applies to lazy-calls. Once they are forced the reference to the function is immediately lost.
A Simple Example¶
Let’s suppose we are looking for underlined headings in a plain text file. These are lines that look like this:
..code:
This is a heading because it is 'underlined'
--------------------------------------------
So what we want to do is to look for pairs of lines of equal length but the second line consists only of “-” characters. Here is how we might use chains to implement that.
We start by converting a file into a line iterator, stripping trailing whitespace.
def lineiter( filename ):
with open( filename, 'r' ) as file:
for line in file:
yield line.rstrip()
Now we can convert that into a lazychain and do lookahead very easily:
def find_headers( filename ):
lines = lazychain(lineiter( filename ))
while lines:
L0, lines = lines.dest() # split off head and tail
if lines:
L1 = lines.head()
if L0 and len(L1) == len(L0):
chars = set(L1)
if len(chars) == 1 and chars.pop() == "_":
# L0 is a header and L1 its underline.
lines = lines.tail()
yield L0
If we tried this on this file:
This is a header
----------------
Lazychains are great. Best thing I ever ate.
This is not a header
~~~~~~~~~~~~~~~~~~~~
But so is this
--------------
End of file.
We would get this:
>>> list(find_headers('data.txt'))
['This is a header', 'But so is this']
More Complex Examples¶
Example - Turner’s Sieve¶
Sometimes it’s nice to work with infinite sequences and Chains can be a good way of doing that. Here’s a well-known algorithm for computing an infinite chain of prime numbers called “Turner’s Sieve” - a bit simpler than the Sieve of Eratosthenes. Here’s how you might write it in a functional language like Haskell.
primes = sieve [2..]
where
sieve (p:xs) = p : sieve [x | x <- xs, rem x p > 0]
It’s not as neat, of course, in Python. But it’s fairly easy to see how to turn the Haskell code into Python.
import itertools
from lazychains import lazychain
def primes():
def sieve( L ):
( p, t ) = L.dest()
return t.filter( lambda x: x % p != 0 ).lazycall( sieve ).new( p )
return sieve( lazychain( itertools.count(2) ) )
>>> p = primes()
>>> itertools.islice( primes, 12 )
chain([2,3,5,7,11,13,17,19,23,29,31,37,...])
Example - Keeping Trails While Searching¶
There are a couple operations that chains do very efficiently. The first is that it is very quick to add another link to the front of a chain, yielding a new chain, that shares but does not affect the old chain.
This comes in very handy when you are doing searches and you want to keep track of the multiple trails that are being explored. For example we might have a maze that we are trying to solve. In this example we represent the maze by a function maze that, given a location and a move (L, R, U or D), returns the new location - or None if the move is unsuccessful.
In this case, we use a chain to keep track of all the previous locations that we have visited. Adding a location onto the start of trail gives you a new trail very cheaply.
from lazychains import chain
from collections import deque
def solve( maze, initial_location, target_location ):
"""This is a simple algorithm for example purposes only."""
paths = deque( [ (initial_location, chain() ) ] )
done = set( initial_location )
while paths:
( loc, moves ) = paths.pop()
for move in "LRUD":
loc1 = maze( loc, move )
if loc1 is not None and loc1 not in done:
done.add(loc1)
moves = moves.new( move ) # Extend the chain of moves
if loc1 == target_location:
yield moves # Found a solution
else:
paths.appendleft( ( loc1, moves ) )
MAZE = [
"###########",
"## ##",
"## ##### ##",
"## ##X## ##",
"## ## ##",
"## ########"
]
INITIAL = (5, 2)
FINAL = (3, 5)
MOVES = { "L": (0, -1), "R": (0, 1), "D": (1, 0), "U": (-1, 0) }
def simple_maze(loc, move):
(row, col) = loc
try:
(rx, cx) = MOVES[move]
if MAZE[ row ][ col ] == "#":
return None
return (row + rx, col + cx)
except IndexError:
return None
And this is it working:
% python3 -i maze.py
>>> next(solve(simple_maze, INITIAL, FINAL))
chain(['U','L','L','L','D','D','D','R','R','R','R','R','R','U','U','U','U'])
>>>